Adapting K-Means Clustering to the Encrypted Domain
During my Engineering degree in Computer Science (Systems specialization), I carried out a final-year engineering project centered on a precise and technically demanding question:
How can the k-means clustering algorithm be adapted to operate directly on encrypted data, without revealing intermediate values or relying on trusted third parties?
This project addresses the gap between theoretical privacy-preserving machine learning and practical implementation under cryptographic constraints.
The goal is not to propose a new clustering method, but to preserve the semantics and behavior of k-means,
- while making it executable under fully homomorphic encryption (FHE) constraints,
- and minimizing trust in the cloud infrastructure.
You can read more in these documents: [Engineering Thesis] · [Defense Slides]
🔢 The k-means Algorithm.
The k-means algorithm is a foundational method in unsupervised learning, widely used for its simplicity and efficiency.
Given a dataset and a predefined number of clusters , k-means iteratively minimizes the within-cluster sum of squared distances through two steps:
Assignment step. Each data point is assigned to the nearest cluster center.
Update step. Cluster centers are recomputed as the mean of their assigned points.
This iterative process continues until convergence.
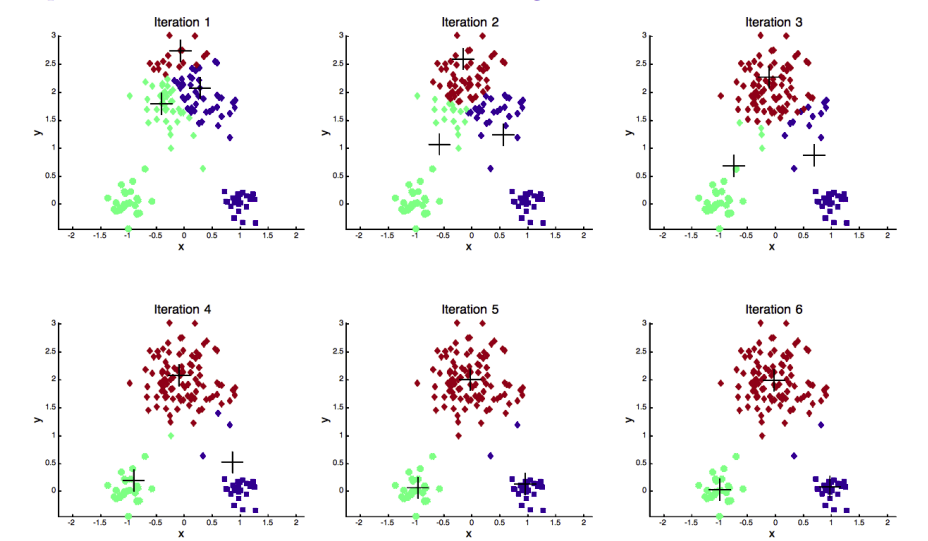
Figure 1 – Illustration of the k-means clustering algorithm (image taken from this thesis).
Why k-means Is Hard to Encrypt
From an engineering standpoint, k-means poses several challenges under homomorphic encryption:
Comparisons : Selecting the closest centroid requires argmin operations, which depend on comparisons not directly supported by FHE schemes.
Divisions : Computing centroids requires division by the number of assigned points, an operation that is expensive in encrypted space.
Floating-point precision : Homomorphic encryption operates over constrained algebraic domains, making precision management non-trivial.
As a result, standard k-means cannot be executed naively on encrypted data.
🧠 Adapting k-means to Homomorphic Encryption
The main engineering contribution of this project lies in the restructuring of the k-means workflow to make it compatible with the constraints imposed by homomorphic encryption. Rather than modifying the objective of the algorithm, the focus was placed on redesigning its internal steps so that they could be executed securely on encrypted data, without revealing intermediate values to the cloud.
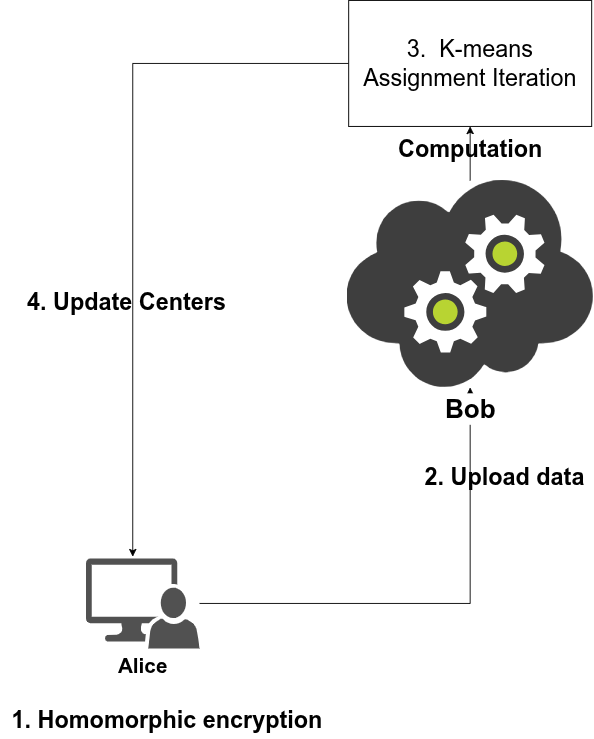
The assignment step represents the most critical challenge. In classical k-means, assigning a data point to the nearest centroid relies on distance comparisons and argmin operations, which are not directly supported in the encrypted domain. To address this limitation, distance comparisons were reformulated as encrypted sign evaluations, allowing relative distances to be compared without decryption. This was achieved using the programmable bootstrapping mechanism provided by the TFHE scheme, which enables the evaluation of custom functions directly on ciphertexts. As a result, cluster assignments could be performed entirely in the encrypted space, eliminating the need for intermediate decryptions and reducing trust assumptions on the cloud server.
The centroid update step was handled with similar care. Since computing new centroids requires division operations, which are costly and impractical under homomorphic encryption, a clear separation of responsibilities was introduced between encrypted and clear-text computations. Encrypted aggregation operations were performed on the cloud side, while divisions were restricted to the data owner, who already holds the decryption keys. To preserve numerical stability and clustering accuracy, additional normalization and scaling techniques were applied to control precision throughout the computation.
Overall, this design preserves the semantic behavior of k-means while enforcing strong privacy guarantees. By carefully adapting each step of the algorithm to the encrypted domain, the solution demonstrates that meaningful clustering can be achieved without sacrificing data confidentiality.
🚀 Conclusion
This engineering project shows that k-means clustering can be systematically adapted to the encrypted domain through careful algorithmic restructuring and cryptography-aware design.
